


Sirius是一个GPU原生SQL引擎,通过标准的Substrait查询格式连接到现有的数据库(如DuckDB),而不需要重写查询或进行重大系统更改。
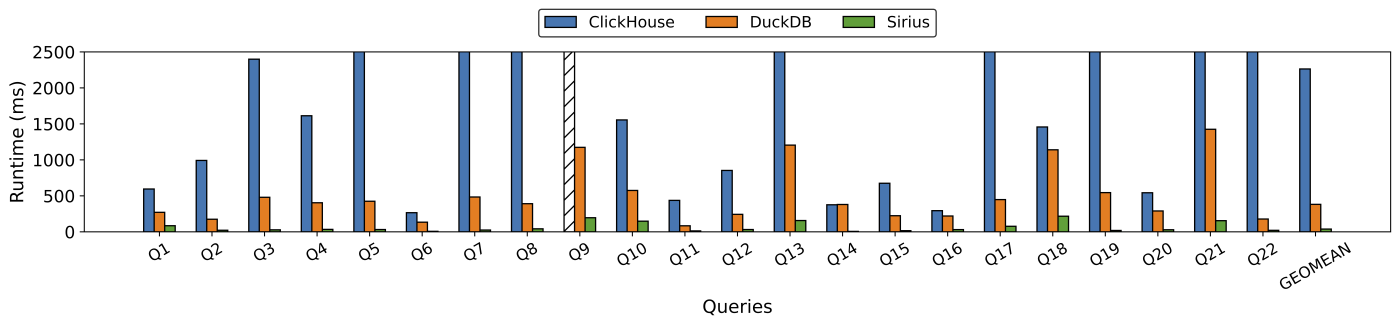
根据Github的性能实验,在SF=100的情况下运行TPC-H,Sirius在相同的硬件租赁成本下,比现有的CPU查询引擎快约10倍,非常适合交互式分析、金融工作负载和ETL作业。
实验设置:
- GPU 实例:GH200@LambdaLabs(每小时 3.2 美元)
- CPU 实例:m7i.16xlarge@AWS(每小时 3.2 美元)
Sirius主要功能:
1、GPU-原生速度
是在相同的硬件租赁成本下,Sirius比DuckDB快10倍,比ClickHouse快60倍,专为gpu构建,目标是基于CPU的SQL引擎的100倍速度。
2、无缝集成
Sirius通过插入DuckDB和Doris等数据库Substrait,在不更改堆栈的情况下加速SQL工作流,支持CPU回退完全兼容。
2、随时随地部署
Sirius支持广泛的部署选项,从云到内部部署,在哪里运行都能提供GPU加速的性能。
Sirius目前支持DuckDB和Doris(即将推出),其他用“*”标记在架构图中:
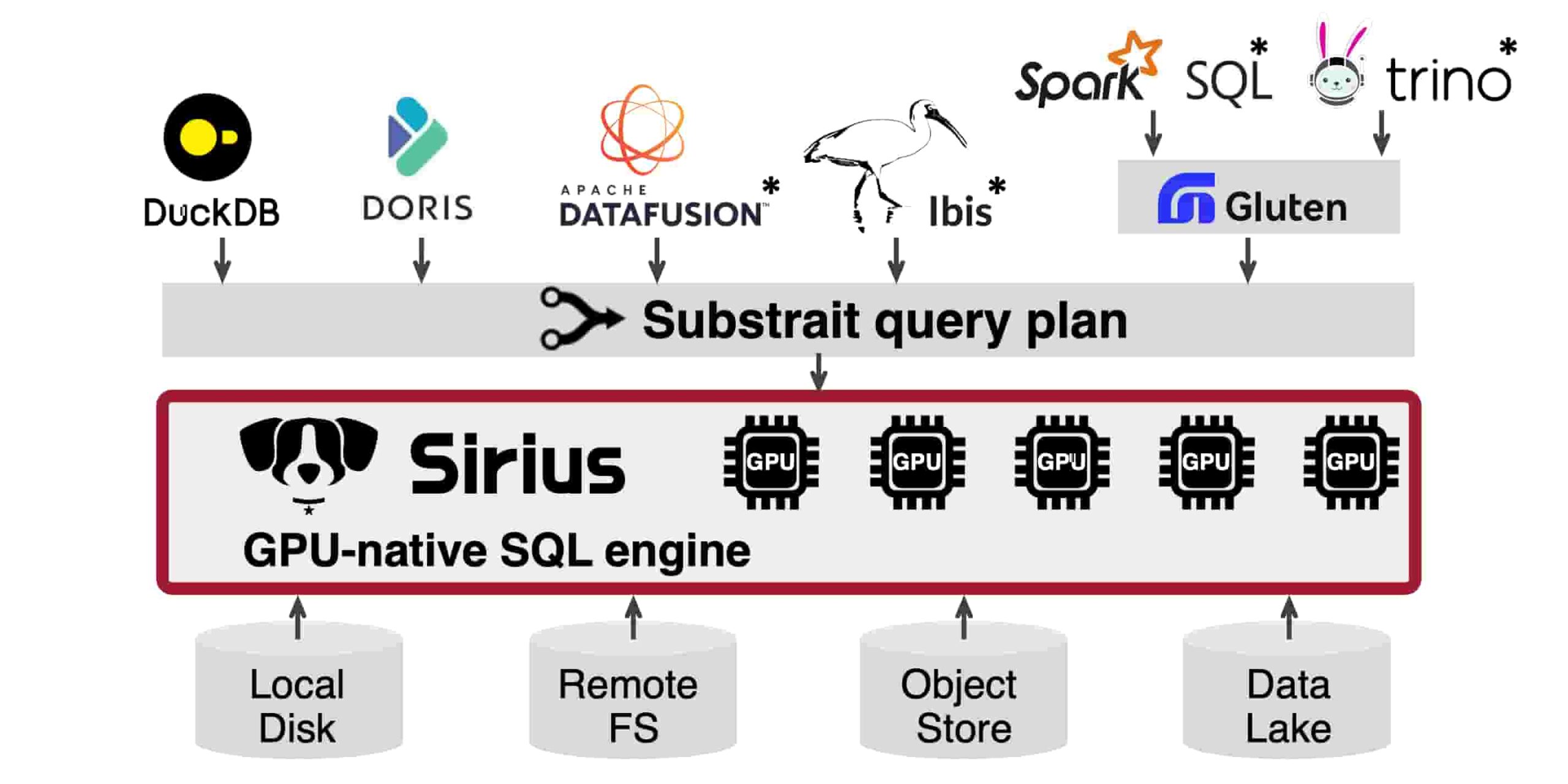
由于Sirius还在不断开发完善阶段,各位在使用时可能会出现个别限制,当遇到以下问题时,为确保查询顺利完成,Sirius会自动优雅降级到DuckDB的CPU置顶模式。
- Sirius的分片执行、批处理、多 GPU、溢出到主机内存/磁盘、分布式执行还在开发阶段,因此在输入数据>GPU缓存区/中间结果>GPU 处理区会报错,数据必须能够完全放下GPU内存;
- 由于底层libcudf使用int32_t存储行ID,因此Sirius存在行数限制(最大支持约20亿行(~2B rows)),不过可通过分片和批处理得到缓解;
- Sirius当前支持INTEGER、BIGINT、FLOAT、DOUBLE、VARCHAR、DATE、TIMESTAMP、DECIMAL数据类型,嵌套类型等还在开发阶段;
- 算子支持包括FILTER、PROJECTION、JOIN、GROUP-BY、ORDER-BY、AGGREGATION、TOP-N、LIMIT、CTE。接下来会支持WINDOW函数、ASOF JOIN等;
- 注意部分空值列不支持仅部分值为NULL的列。
展望未来,Sirius还会开发以下功能:
- 磁盘/存储支持
- 更多SQL算子与数据类型
- 多GPU与多节点扩展
- 支持更多数据库引擎(如Spark、PostgreSQL等)
(本文由美国主机侦探原创,转载请注明出处“美国主机侦探”和原文地址!)

微信扫码加好友进群
主机优惠码及时掌握

QQ群号:164393063
主机优惠发布与交流


{kind=link}
{kind=link}