


AWS的Amazon S3 Tables为表格数据提供了一种优化的存储方式,比如每日购买交易数据、流式传感器数据和广告曝光量数据等,可以使用Amazon Athena、Amazon EMR和Apache Spark等流行的查询引擎来查询数据。与自行管理的表存储相比,查询性能最高能提升3倍,每秒事务处理量最多可提高10倍。本篇教程将详细介绍如何用AWS的Amazon S3存储表格数据。
Iceberg已成为管理Parquet文件最常用的方式,很多AWS客户会用Iceberg来查询数十亿计的文件,这些文件中可能包含PB级甚至EB级的数据。

一、表存储桶、表和命名空间
Amazon S3(全程为Amazon Simple Storage Service)是一种对象存储服务,提供可扩展性和数据可用性,同时也注重安全性。Amazon S3适用于在线归档、灾难恢复以及数据展示等多种使用场景。Amazon S3目前为新用户提供了长达12个月的免费试用,期间提供5GB 标准存储、20000 个 Get 请求和 100 GB 的数据传出量,容量不限,提供超过250中专注于存储的解决方案。
点击访问AWS官网:https://www.amazonaws.cn/(免费12个月试用Amazon S3)
表存储桶是Amazon S3存储桶的第三种类型,与现有的通用存储桶和目录存储桶并列。你可以把表存储桶看作一个分析型数据仓库,能存储各种结构的Iceberg表。Amazon S3 Tables具有S3原本的持久性、可用性、可扩展性和高性能特征,还能自动优化存储,从而最大限度地提高查询性能并降低成本。
每个表存储桶都要部署在特定的AWS区域中,存储桶名称在当前AWS账户下的对应区域中必须是唯一的。你可以通过指定存储桶的ARN来引用对应的存储桶,也可以用资源策略进行访问控制。另外每个存储桶的表通过命名空间进行逻辑分组。
表是存储在表存储桶中的结构化数据集。和表存储桶一样,表也有对应的ARN和资源策略,并且隶属于存储桶的某个命名空间。表是全托管形式,还有可配置的持续自动维护功能,包括压缩、旧快照管理和删除未引用的文件。每个表都有一个S3 API端点,用于实现存取数据等操作。
为了简化访问管理,可以在访问策略中引用命名空间。
二、使用命令行创建存储桶和表现在我们来创建一个存储桶,然后在存储桶里存一两个表。我用的是AWS命令行工具(AWS CLI),你也可以使用AWS管理控制台和API。为了方便展示,我通过jq把冗长命令的输出进行管道化处理,只展示最相关的值。
1、创建一个表存储桶
$ aws s3tables create-table-bucket –name jbarr-table-bucket-2 | jq .arn
“arn:aws:s3tables:us-east-2:123456789012:bucket/jbarr-table-bucket-2”
用表存储桶的ARN创建一个环境变量:
$ export ARN=”arn:aws:s3tables:us-east-2:123456789012:bucket/jbarr-table-bucket-2″
然后列出所有表存储桶:
$ aws s3tables list-table-buckets | jq .tableBuckets[].arn
“arn:aws:s3tables:us-east-2:123456789012:bucket/jbarr-table-bucket-1”
“arn:aws:s3tables:us-east-2:123456789012:bucket/jbarr-table-bucket-2”
可以用多种方式来访问表和向表中填充数据。在这个实验中安装了Apache Spark,然后使用命令行参数调用Spark shell,以使用适用于Apache Iceberg的Amazon S3 Tables Catalog软件包,并将mytablebucket设置为表的ARN。
创建一个命名空间(mydata),用来对表进行分组:
scala> spark.sql(“””CREATE NAMESPACE IF NOT EXISTS mytablebucket.mydata”””)
然后在命名空间中,创建一个简单的Iceberg表:
spark.sql(“””CREATE TABLE IF NOT EXISTS mytablebucket.mydata.table1
(id INT,
name STRING,
value INT)
USING iceberg
“””)
执行以下s3tables命令,看看命名空间和表是否创建成功:
$ aws s3tables list-namespaces –table-bucket-arn $ARN | jq .namespaces[].namespace[]
“mydata”
$
$ aws s3tables list-tables –table-bucket-arn $ARN | jq .tables[].name
“table1”
接着回到Spark shell,在表中添加几行数据:
三、使用控制台创建存储桶和表spark.sql(“””INSERT INTO mytablebucket.mydata.table1
VALUES
(1, ‘Jeff’, 100),
(2, ‘Carmen’, 200),
(3, ‘Stephen’, 300),
(4, ‘Andy’, 400),
(5, ‘Tina’, 500),
(6, ‘Bianca’, 600),
(7, ‘Grace’, 700)
“””)
你也可以使用Amazon S3控制台来创建和管理表存储桶。点击 “Table buckets(表存储桶)”,就能快速开始创建存储桶。

在创建第一个存储桶之前,可以先点击 “Enable integration(启用集成)” 功能。这样就可以从Amazon Athena、Amazon Redshift、Amazon EMR和其他AWS查询引擎访问表存储桶。(你也可以先创建存储桶,等后面需要的时候再启用这个功能。)
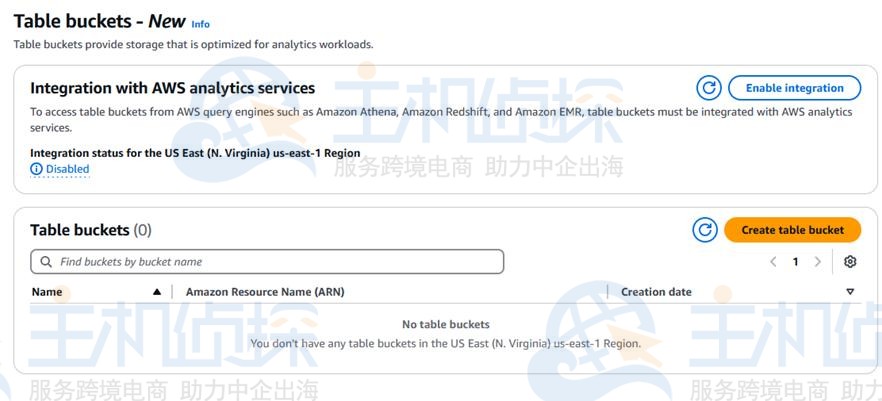
仔细阅读弹出的说明信息,然后点击 “Enable integration(启用集成)”。集成功能启用时,会自动在AWS Glue Data Catalog中创建对应的IAM角色和条目。
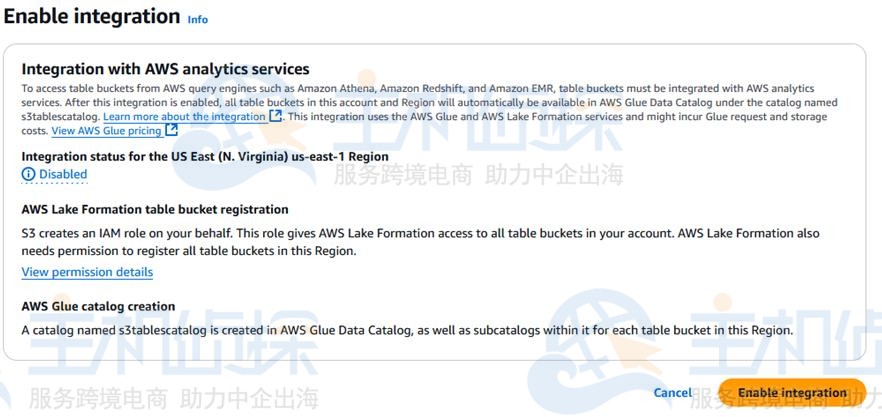
等几秒,集成启用成功。然后点击 “Create table bucket(创建表存储桶)”,继续后面的操作。
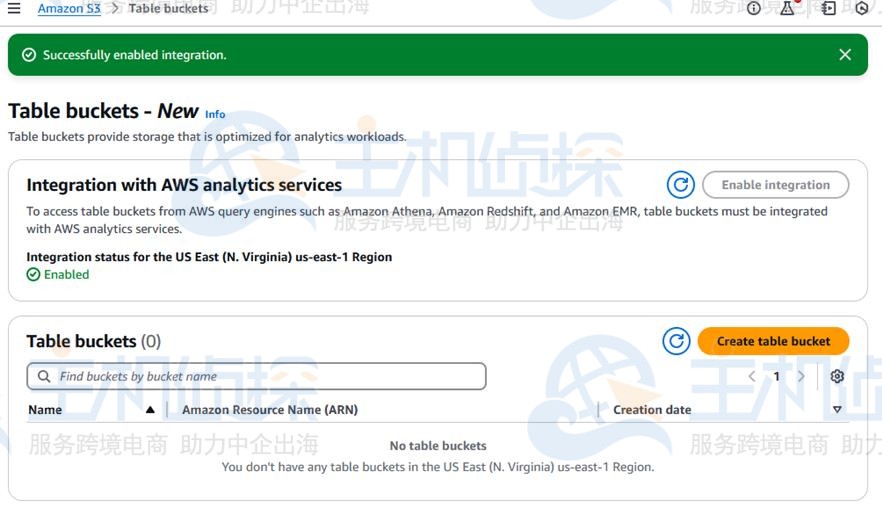
输入名称(jbarr-table-bucket-3),然后点击 “Create table bucket(创建表存储桶)”。
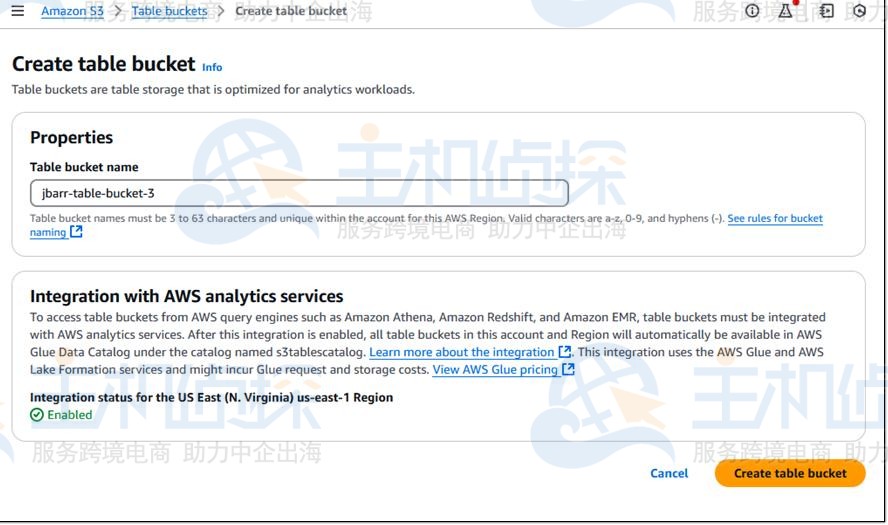
表存储桶创建成功后,你就可以继续创建表和使用表了。
四、表维护表存储桶可以自动处理一些重要的维护任务。要是你用自托管的Iceberg表,这些维护工作就得你自己来做。为了减轻你的负担,让你有更多时间去处理和业务相关的表设计和管理,AWS系统会自动执行以下维护操作:
1、压缩
把多个小表对象合并成一个较大的对象,以提高查询性能,目标是生成64MiB至512MiB大小的文件。新对象会被重写为新快照。
2、快照管理
根据配置,自动标记过期表快照并最终删除表快照。配置选项包括保留快照的最小数量和快照保留的最长时间。过期快照会被标记为非当前快照,然后在指定天数后删除。
3、删除未引用文件
删除没有被任何表快照引用的对象。
五、注意事项1、AWS集成:S3 Tables与AWS Glue Data Catalog的集成还在试用阶段。集成后可以通过Amazon Athena、Amazon Redshift、Amazon EMR和Amazon QuickSight等AWS分析服务来查询和可视化S3表存储桶中的数据。
2、S3 API支持:表存储桶支持相关的S3 API函数,包括GetObject、HeadObject、PutObject和分段上传操作。
3、安全性:会自动加密表存储桶中存储的所有对象。表存储桶配置为强制屏蔽公共访问。
4、定价:需要支付存储费用、请求处理费用、对象监控费用和压缩费用。更多信息请查看《亚马逊云存储Amazon S3收费标准》。
5、区域:目前支持此功能的AWS区域有:美国东部(俄亥俄)、美国东部(弗吉尼亚北部)和美国西部(俄勒冈)区域。
相关推荐:
(本文由美国主机侦探原创,转载请注明出处“美国主机侦探”和原文地址!)

微信扫码加好友进群
主机优惠码及时掌握

QQ群号:164393063
主机优惠发布与交流



{kind=link}
{kind=link}