


Hostinger OpenClaw VPS支持一键部署OpenClaw,无需安装Docker、配置VPS或自行维护OpenClaw实例,启动OpenClaw后,用户可以通过hPanel管理该应用程序。本文主要介绍Hostinger OpenClaw VPS创建知识库聊天机器人的完整流程,教程仅供参考,有需要的朋友可以了解一下。

一、Hostinger部署OpenClaw
使用Hostinger的自托管OpenClaw方案部署OpenClaw,无需手动设置VPS,即可确保您的聊天机器人始终在线。知识库聊天机器人需要一个持久的环境来访问文档、回答问题,并连接到Telegram、Slack、WhatsApp等渠道或网站插件。
1、前往Hostinger官网,点击“一键OpenClaw”。
2、进入OpenClaw页面,选择一个托管的OpenClaw方案。
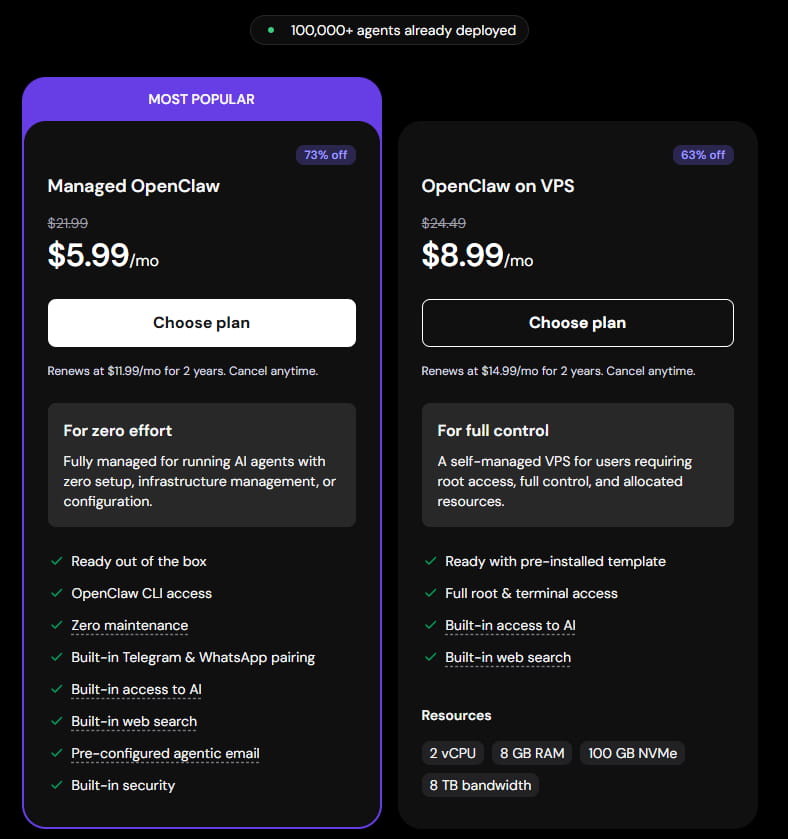
Hostinger优惠码:IDCSPY(虚拟主机高达86%折扣、云主机高达78%折扣,VPS主机高达73%折扣)
相关推荐:《Hostinger OpenClaw VPS方案:无需编码一键部署低至$5.84立享全天候AI代理》
3、在hPanel中完成设置。
4、打开OpenClaw环境。
5、请确认已配置人工智能积分或您首选的模型提供商。
6、为知识库聊天机器人创建一个专用工作区。
如果用户是一位需要完全自定义的开发者,还可以在VPS上运行OpenClaw,用户可以获得完整的root权限和服务器的完全控制权。
Hostinger VPS主机方案推荐
| 方案 | CPU | 内存 | 硬盘 | 流量 | 优惠价/月 |
| KVM 1 | 1vCPU | 4GB | 50GB NVMe | 4TB | $5.84 |
| KVM 2 | 2vCPU | 8GB | 100GB NVMe | 8TB | $8.09 |
| KVM 4 | 4vCPU | 16GB | 200GB NVMe | 16TB | $11.69 |
| KVM 8 | 8vCPU | 32GB | 400GB NVMe | 32TB | $23.39 |
《点击进入官网选购》
相关推荐:《Hostinger Linux VPS安装Docker并部署OpenClaw教程》
二、创建聊天机器人工作区创建一个专用的OpenClaw工作区,将聊天机器人的文档、指令、内存和频道设置与其他项目隔离开来。这样可以防止智能体将不相关的上下文信息混入知识库答案中。
使用与聊天机器人用途相符的清晰工作区名称,例如support-kb、product-docs、internal-faq或policy-assistant。在工作区内,创建一个名为knowledge/的文件夹,用于存放聊天机器人需要使用的文档,包括常见问题解答、手册、政策、Markdown文件或PDF内容。
一个简单的工作区结构可以如下所示:
support-kb/
├── knowledge/
│├── refund-policy.md
│├── shipping-faq.md
│ └── product-manual.pdf
├── prompts/
│ └── chatbot-instructions.md
└── logs/
将已批准、已过期和草稿文档分别保存在不同的文件夹中。聊天机器人应该只接收已批准的文件,因为过期的政策或未完成的记录可能会导致回答错误。
在连接任何聊天渠道之前,添加一个简短的指令文件,定义聊天机器人的角色。例如:
三、选择知识来源You are a knowledge base chatbot for customer support. Answer only from the documents in the knowledge folder. If the answer is not available, say that the knowledge base does not contain the answer. Do not guess, invent policy details, or use unrelated workspace files.
请根据您已批准的聊天机器人内容所在的位置选择知识库。OpenClaw只有在搜索到正确的文档时才能提供可靠的答案,因此请避免将草稿、过时的文件和不相关的笔记混放在同一个知识库中。
对于大多数知识库聊天机器人来说,最佳的起点是在工作区内创建一个结构化的文件夹:
support-kb/
└── knowledge/
├── faq/
├── policies/
├── product-docs/
└── troubleshooting/
此文件夹用于存放PDF文件、Markdown文件、文本文件、常见问题解答、用户手册、新手入门文档或支持政策。这种设置易于管理,方便重新索引,非常适合第一个聊天机器人项目。
根据您的内容选择源格式:
首先选择迁移需求最小的源文件。如果您的支持回复已经是Markdown格式,请继续使用Markdown。如果您的产品手册是PDF格式,请继续使用PDF。
四、使用MemClaw添加检索或内存功能如果聊天机器人需要跨会话记住项目上下文、决策和工作区指令,请添加MemClaw。MemClaw为OpenClaw提供持久的项目记忆,因此每次重新打开聊天机器人时,代理程序都不会从空白上下文开始。
对于知识库聊天机器人,可以使用MemClaw来存储稳定的上下文信息,例如聊天机器人的用途、已批准的知识来源、响应规则、升级规则以及重要决策。例如,MemClaw可以记住聊天机器人只能回答来自knowledge/文件夹的问题,避免回答草稿文档,并且对于账单或法律问题,应进行升级处理,而不是猜测。
将以下信息添加到聊天机器人内存中:
Project: support-kb chatbot Purpose: Answer customer questions using approved documents from the knowledge folder. Approved source: Use only files inside /knowledge/approved/. Do not use: Draft files, archived policies, private notes, or unrelated workspace files. Response rules: Answer from the knowledge base when possible. Say the knowledge base does not contain the answer if no source is available. Do not invent policy details, prices, timelines, or guarantees. Escalation rules: Send refund disputes, legal questions, account access issues, and unclear policy questions to a human.
添加内存后,在新会话中进行测试。询问OpenClaw聊天机器人可以回答哪些问题、应该使用哪个文件夹,以及当知识库中没有答案时应该怎么做。如果它无需重新输入设置详情就能给出正确的规则,则说明内存层工作正常。
保持MemClaw的专注性。不要将完整的用户手册、冗长的PDF文件或所有支持对话都存储在内存中。只需存储操作规则和项目上下文,然后让知识库处理文档检索即可。
五、将文档添加到知识库仅将已批准的文档添加到聊天机器人的知识库中,以便OpenClaw在回答用户问题时能够检索到准确的信息。知识库应包含聊天机器人被允许使用的文件,而不是工作区中的所有文档。
首先将源文件放置在knowledge/approved/文件夹中:
support-kb/
└── knowledge/
├── approved/
│ ├── refund-policy.md
│ ├── shipping-rules.md
│ ├── product-setup-guide.pdf
│ └── troubleshooting-faq.md
├── drafts/ └── archive/
添加前,请:
- 删除重复或过时的章节。
- 将草稿内容移至单独的文件夹。
- 添加与用户真实问题相符的标题。
- 尽可能每个文件只保留一项政策、产品或工作流程。
- 如果OpenClaw无法可靠地读取扫描的PDF文件,则将其转换为文本文件。
然后让OpenClaw导入已批准的文件夹。例如:
Ingest all documents in /knowledge/approved/ into the chatbot knowledge base. Use these files as the approved source for support answers.
数据导入后,在将聊天机器人连接到用户之前,请先验证索引:
List all documents currently available in the knowledge base.
测试一个已知答案的问题:
What does the refund policy say about digital products?
答案应与已批准的源文件一致。如果OpenClaw从错误的文档中获取答案、遗漏关键细节或使用过时的信息,请先修复源文件夹,然后再重新导入文件。干净的知识库比庞大的知识库更重要。
六、配置聊天机器人的回答行为配置聊天机器人的回答行为,使OpenClaw能够知道该回答什么问题、信任哪些信息来源以及何时应该升级处理,而不是靠猜测。这一步骤将知识库从一个文档搜索工具转变为一个可靠的聊天机器人。
在工作区中创建一个简短的说明文件,例如:
support-kb/
└── prompts/
└── chatbot-instructions.md
使用指令文件定义聊天机器人的角色、来源规则、语气和限制:
You are a knowledge base chatbot for customer support. Answer rules: Use only approved documents from /knowledge/approved/. Answer in clear, direct language. Mention the source document when possible. Do not invent prices, policy details, timelines, or guarantees. If the knowledge base does not contain the answer, say so. Tone: Be concise, helpful, and professional. Use step-by-step instructions for setup or troubleshooting questions. Use short paragraphs for policy answers. Escalation rules: Escalate refund disputes, legal questions, account access issues, billing exceptions, and unclear policy questions to a human.
如果您使用MemClaw来管理持久化项目内存,请将相同的规则添加到MemClaw中。这有助于OpenClaw在会话之间保持聊天机器人的运行规则。
将OpenClaw连接到用户提问的频道,如WhatsApp、Telegram等以便聊天机器人可以接收查询并从知识库返回答案。
七、使用真实问题测试聊天机器人在正式发布前,请使用真实用户问题测试聊天机器人,以确认其能够检索正确的文档并遵循预设的回答规则。
先列出15-20个问题,这些问题应涵盖聊天机器人的主要使用场景。问题应包括简单问题、多步骤问题、表述不清的问题以及聊天机器人不应该回答的问题。
请对照已批准的源文档检查每个答案。好的答案应使用正确的文件,包含关键条件或限制,并避免添加知识库中不存在的细节。
用简单的测试日志记录结果:
Question:
Expected source:
Chatbot answer:
Correct source used? Yes/No
Answer accurate? Yes/No
Escalation needed? Yes/No
Fix needed:
首先解决最严重的问题。如果聊天机器人使用了错误的信息源,请清理知识库或改进文件名和标题。如果它在答案缺失的情况下进行猜测,请完善指令文件。如果它提供的信息过时,请删除旧文档并重新导入已批准的文件夹。
每次修复后都要重新测试相同的问题。只有当聊天机器人能够回答来自正确来源的已知问题,并将超出知识库范围的问题上报给上级时,它才能真正为真实用户提供服务。
(本文由美国主机侦探原创,转载请注明出处“美国主机侦探”和原文地址!)

微信扫码加好友进群
主机优惠码及时掌握

QQ群号:164393063
主机优惠发布与交流


{kind=link}
{kind=link}