


利用AWS S3的规模、耐用性、低成本、安全性和存储选项,客户通常将数百万或数十亿个对象存储在单个Amazon Simple Storage Service(Amazon S3)存储桶中。今天想向大家介绍一下Amazon S3批量操作,用户可以使用此新功能以简单明了的方式轻松处理数百、数百万或数十亿个S3对象。可以将对象复制到另一个bucket,设置标签或访问控制列表(ACL),从Glacier启动还原,或在每个bucket上调用AWS Lambda函数。
亚马逊S3基于S3对库存报告的现有支持,可以使用报告或CSV文件来驱动批处理操作。不必编写代码,设置任何服务器机群,也不必弄清楚如何划分工作并将其分配给机群。相反只需点击几下,就可以在几分钟内创建一个作业,AWS S3则使用大量的幕后并行来处理这项工作。
>>点击免费试用AWS S3>>>(长达12个月)

一、运行亚马逊S3批量操作
前提条件:为亚马逊S3存储桶(jbarr-batch-camera)启用了库存报告,并将报告发送到jbarr批量库存:
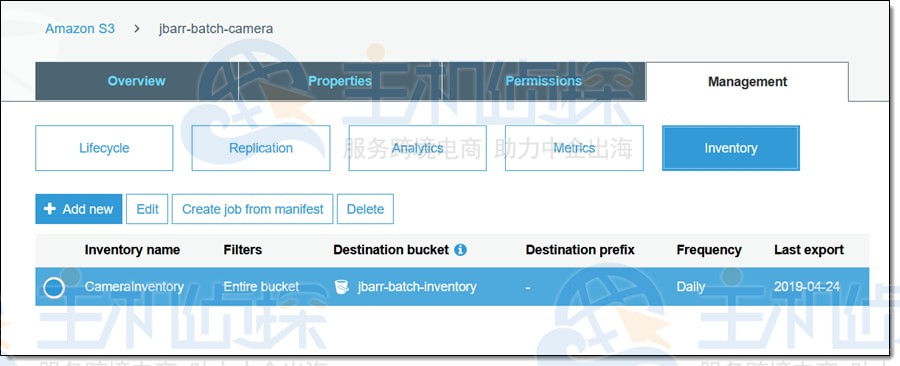
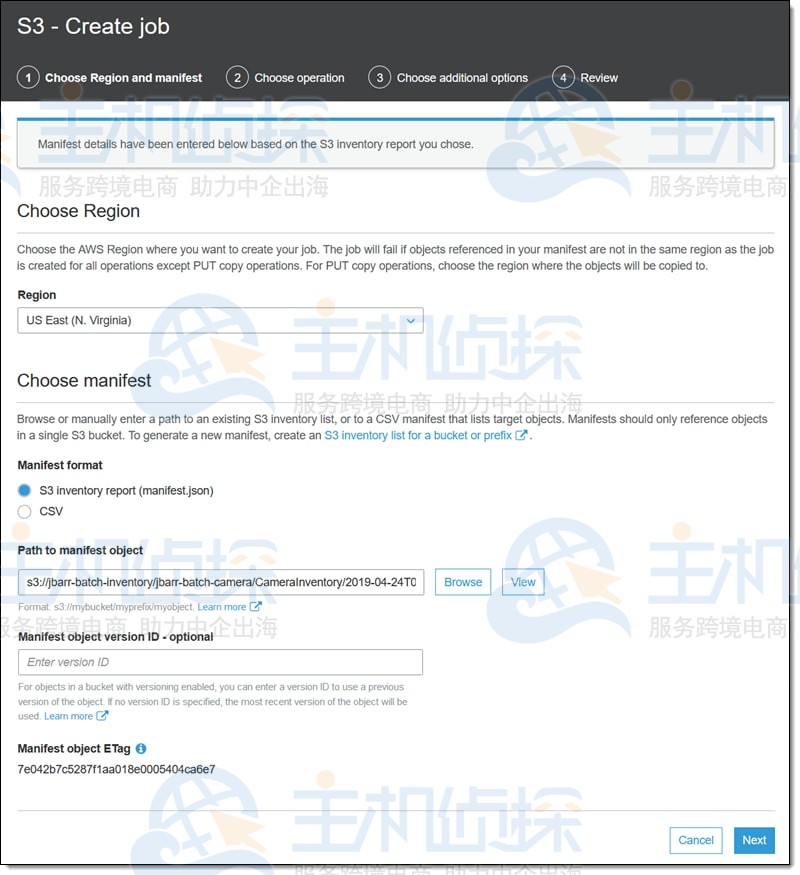
选择所需的清单项,然后单击“从清单创建作业”开始(也可以在浏览桶列表时单击“批处理操作”)。所有相关信息都已填写,但如果需要,可以选择清单的早期版本(此选项仅适用于清单存储在启用了版本控制的存储桶中的情况),单击“下一步”继续:
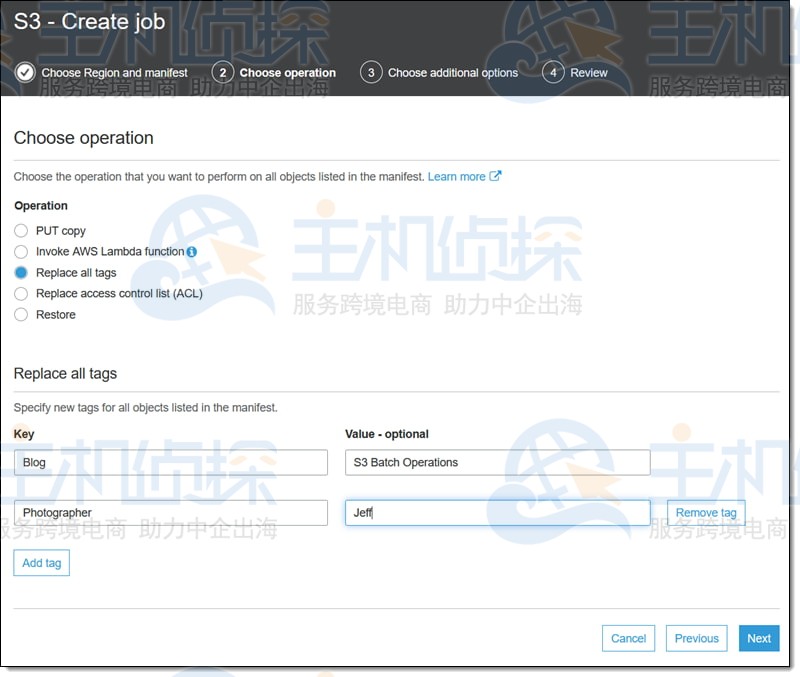
进入操作选择(替换所有标记),填写有关信息项,然后单击下一步:
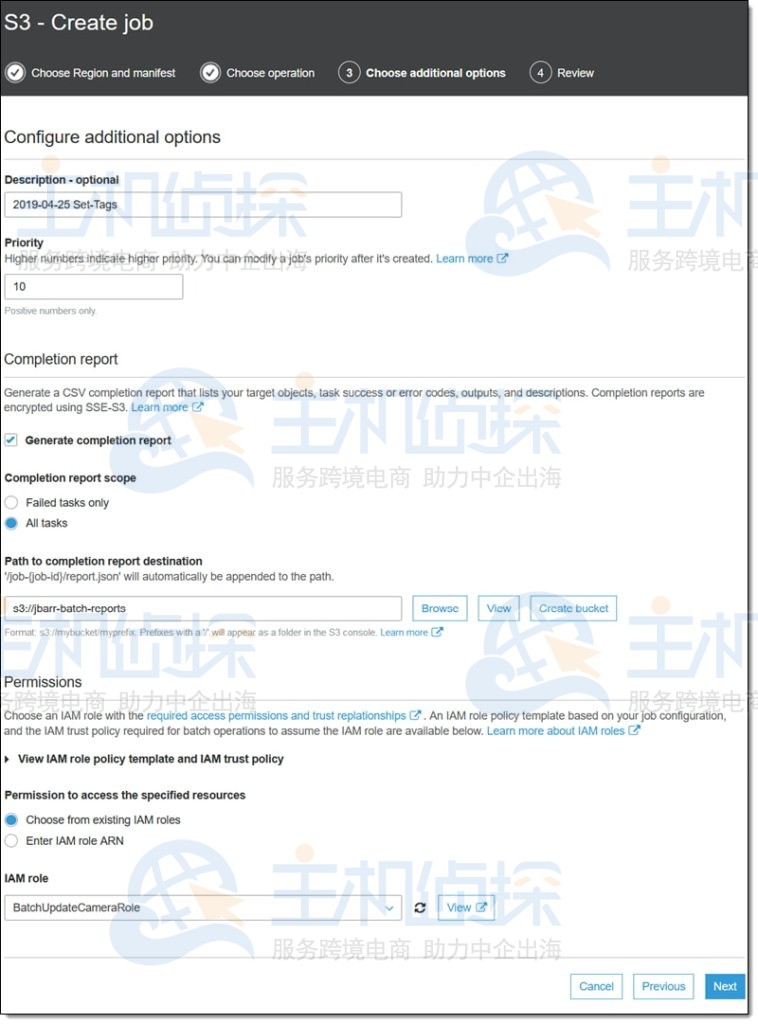
为亚马逊S3批量操作输入一个名称,设置其优先级,并请求一份包含所有任务的完成报告。然后为报告选择一个bucket,并选择一个授予必要权限的IAM角色(控制台还显示了一个角色策略和一个我可以复制和使用的信任策略),然后单击下一步:
最后查看并确认然后单击“创建作业”:
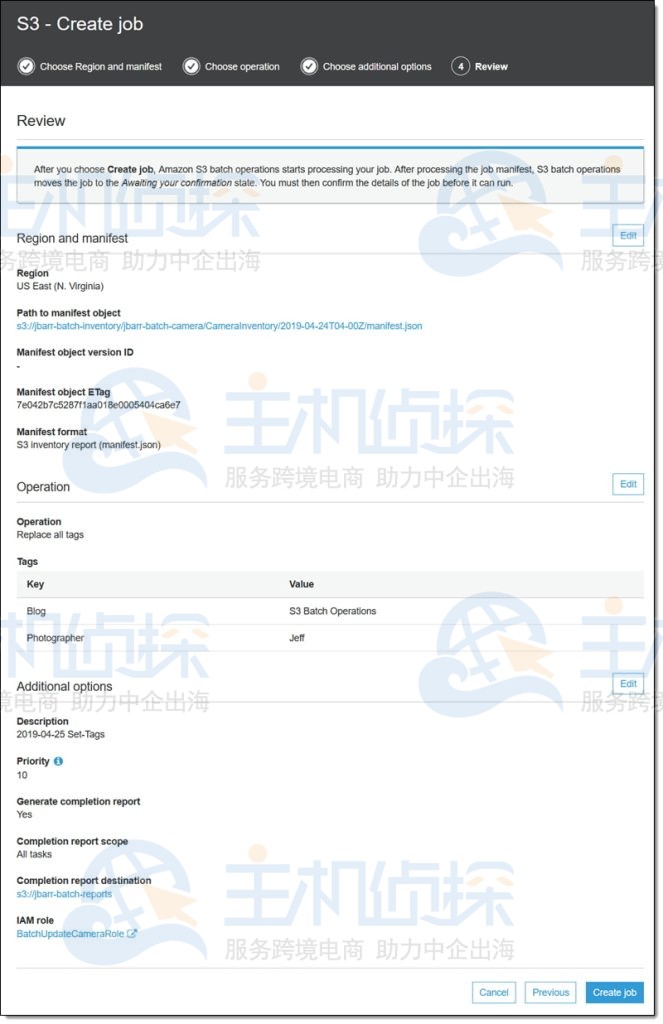
作业进入“正在准备”状态,S3批量处理操作检查清单并进行其他验证,作业进入等待确认状态(这仅在用户使用控制台时发生),选择它并单击确认并运行:
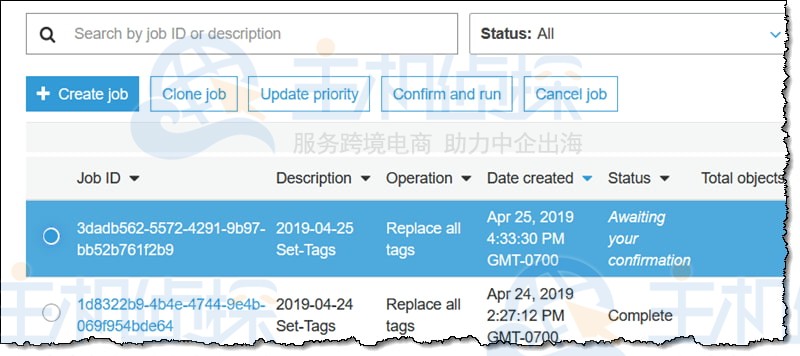
查看确认信息(未显示),以确保了解要执行的操作,然后单击“运行作业”,作业进入就绪状态,并在此后不久开始运行,完成后它将进入完成状态:
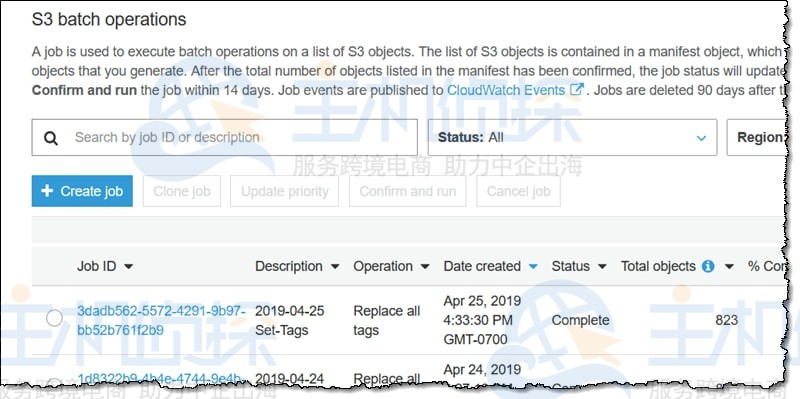
如果正在运行一个处理大量对象的作业,可以刷新此页面以监视状态。
注:在处理完前1000个对象后,亚马逊S3会检查和监控整体故障率,如果故障率超过50%,将停止作业。
报告包含每个对象的信息如下所示:
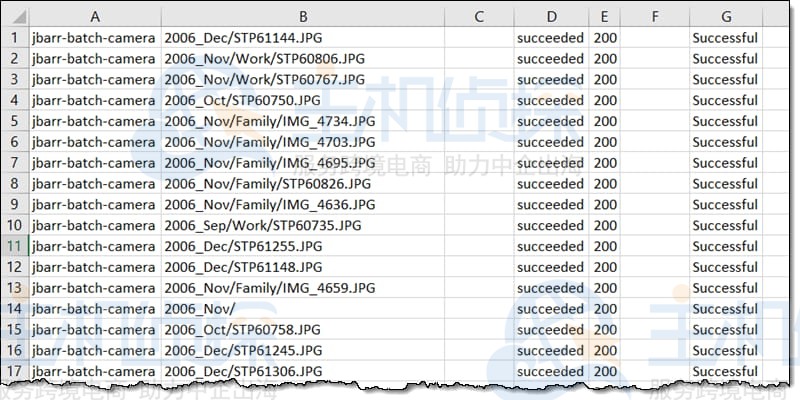
以下是其他亚马逊S3内置批量处理操作概述:
1、PUT复制操作:复制对象并控制存储类、加密、访问控制列表、标签和元数据,可以将对象复制到同一个bucket中以更改其加密状态,还可以将它们复制到另一个地区,或复制到另个AWS帐户拥有的存储桶中。
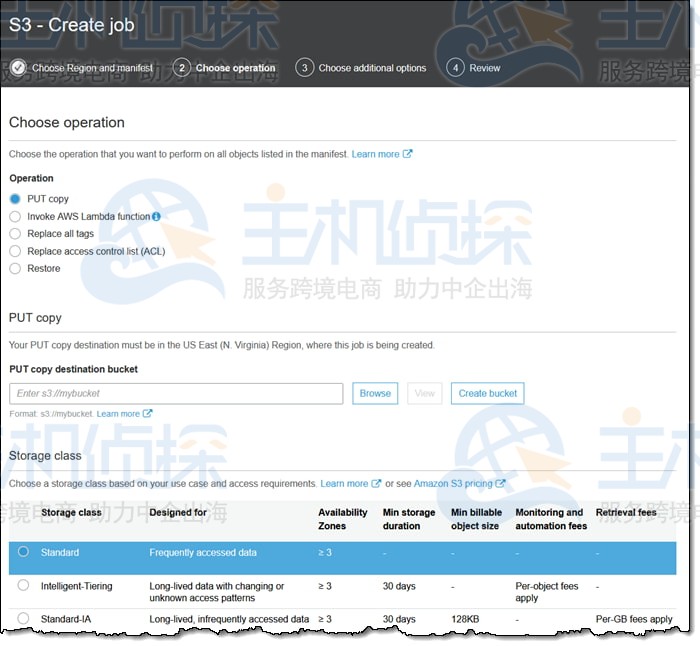
2、替换访问控制列表(ACL)操作:对授予的权限进行控制:
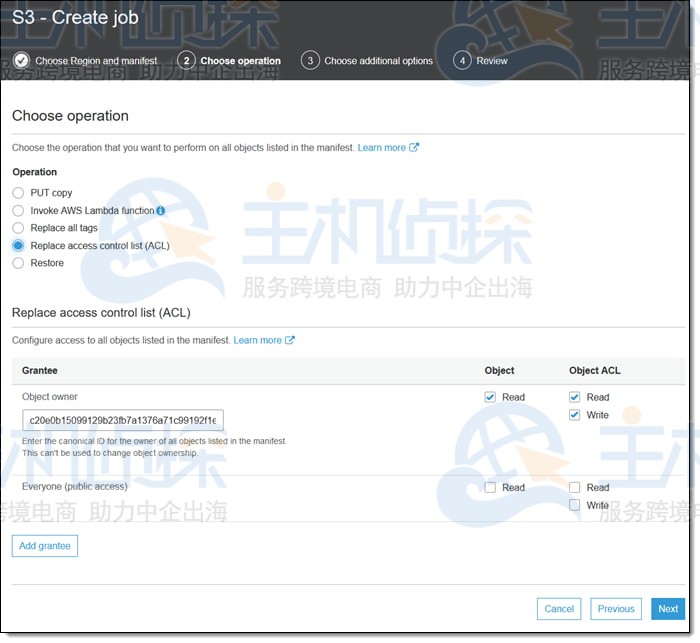
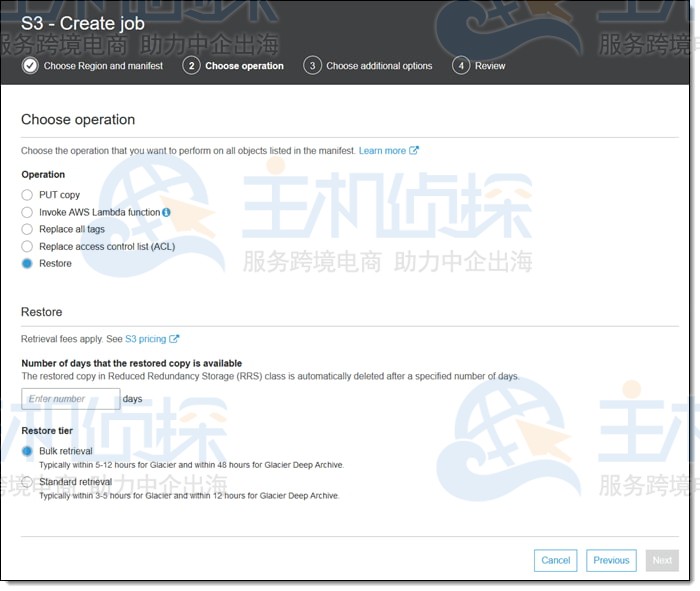
3、Restore操作:将从Glacier或Glacier Deep Archive存储类启动对象级还原:
推荐阅读:
(本文由美国主机侦探原创,转载请注明出处“美国主机侦探”和原文地址!)

微信扫码加好友进群
主机优惠码及时掌握

QQ群号:164393063
主机优惠发布与交流


{kind=link}
{kind=link}