


Grafana是一款开源数据可视化和监控工具,其构建原则是让组织中的每个人都可以访问数据,也是目前网络架构和应用分析中最流行的时序数据展示工具之一。在本篇教程中将介绍如何使用Grafana配置服务器故障实时警报,并利用来自Prometheus的可靠指标进行监控。
Grafana提供了一个统一的可观测性层,将指标、日志和告警整合到一个界面中。将Grafana与Prometheus配合使用时可实现近乎实时地检测服务器和服务故障,制定基于指标、阈值和趋势的灵活告警规则,并设置来自电子邮件、Slack、PagerDuty等的多渠道通知,同时缩短平均检测时间 (MTTD) 和平均修复时间 (MTTR)。

一、设置前提条件
1、一台用于监控的Linux服务器/VPS/虚拟机
购买参考:
《2026年稳定高性价比国内/国外VPS云服务器商家整理汇总》
2、已安装并正在抓取指标的Prometheus
3、已安装并通过浏览器访问的Grafana
4、目标服务器上运行的Node Exporter
二、安装和配置Node ExporterNode Exporter提供系统级指标,例如CPU、内存、磁盘和网络使用情况。
wget https://github.com/prometheus/node_exporter/releases/download/v1.8.1/node_exporter-1 8.1.linux-amd64.tar.gz
tar -xvf node_exporter-*.tar.gz cd node_exporter-*
./node_exporter
默认情况下,指标数据可在以下地址访问:
三、将Node Exporter添加到Prometheushttp://<服务器IP>:9100/metrics
编辑prometheus.yml文件:
scrape_configs:
– job_name: “node_exporter” static_configs:
– targets: [“<服务器IP>:9100”]
请务必将“<服务器IP>”替换为你的实际服务器IP地址)重新加载Prometheus并确认指标数据已显示在Prometheus UI中。
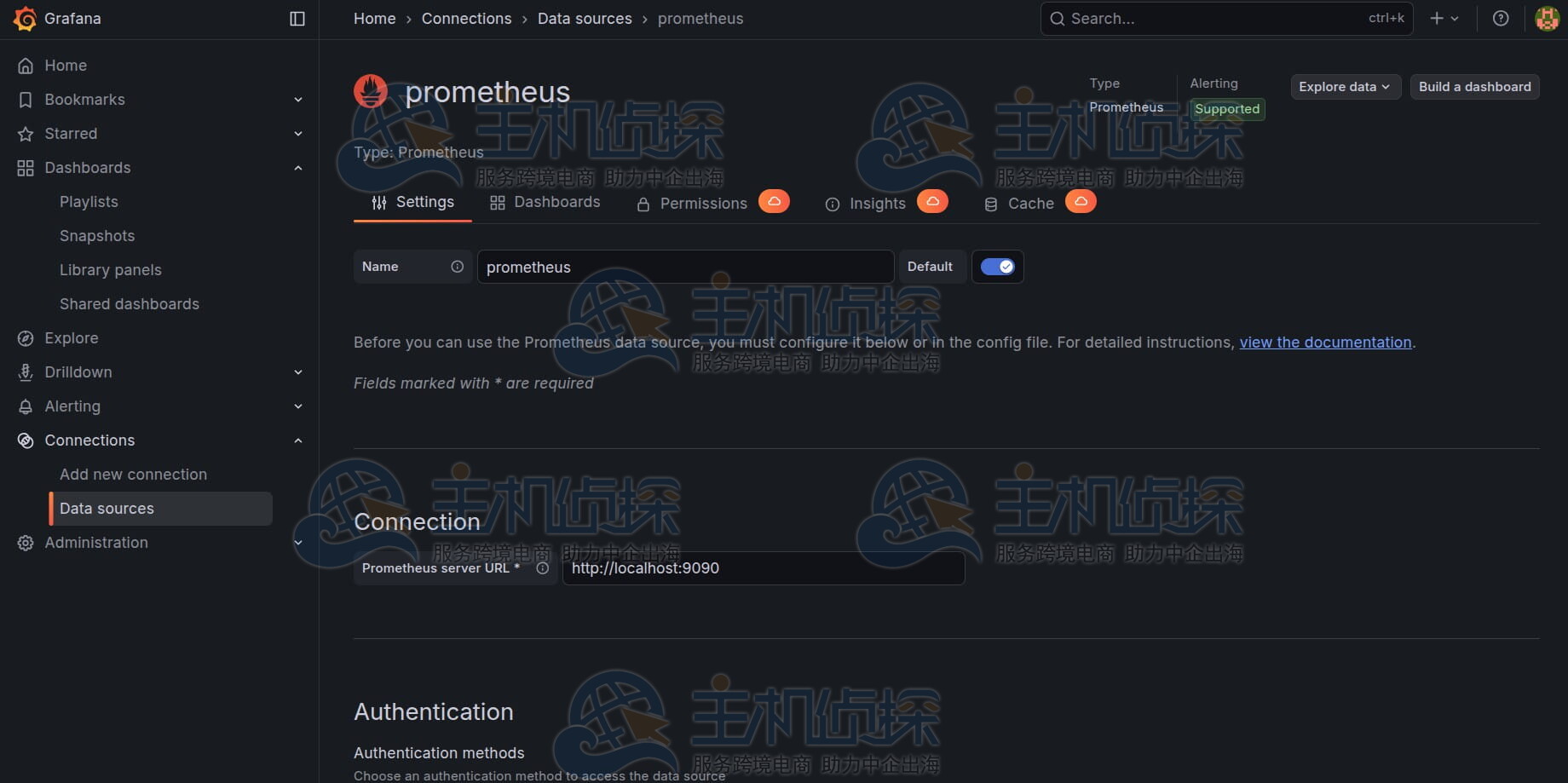
四、在Grafana中添加Prometheus作为数据源Grafana由Grafana Labs开发和维护,而Prometheus是由云原生计算基金会 (CNCF) 管理的开源监控系统。在Grafana中添加Prometheus作为数据源请参考以下步骤:
1、登录Grafana
2、导航至“连接”>“数据源”
3、选择Prometheus
4、设置URL(例如http://localhost:9090)
5、点击“保存并测试”
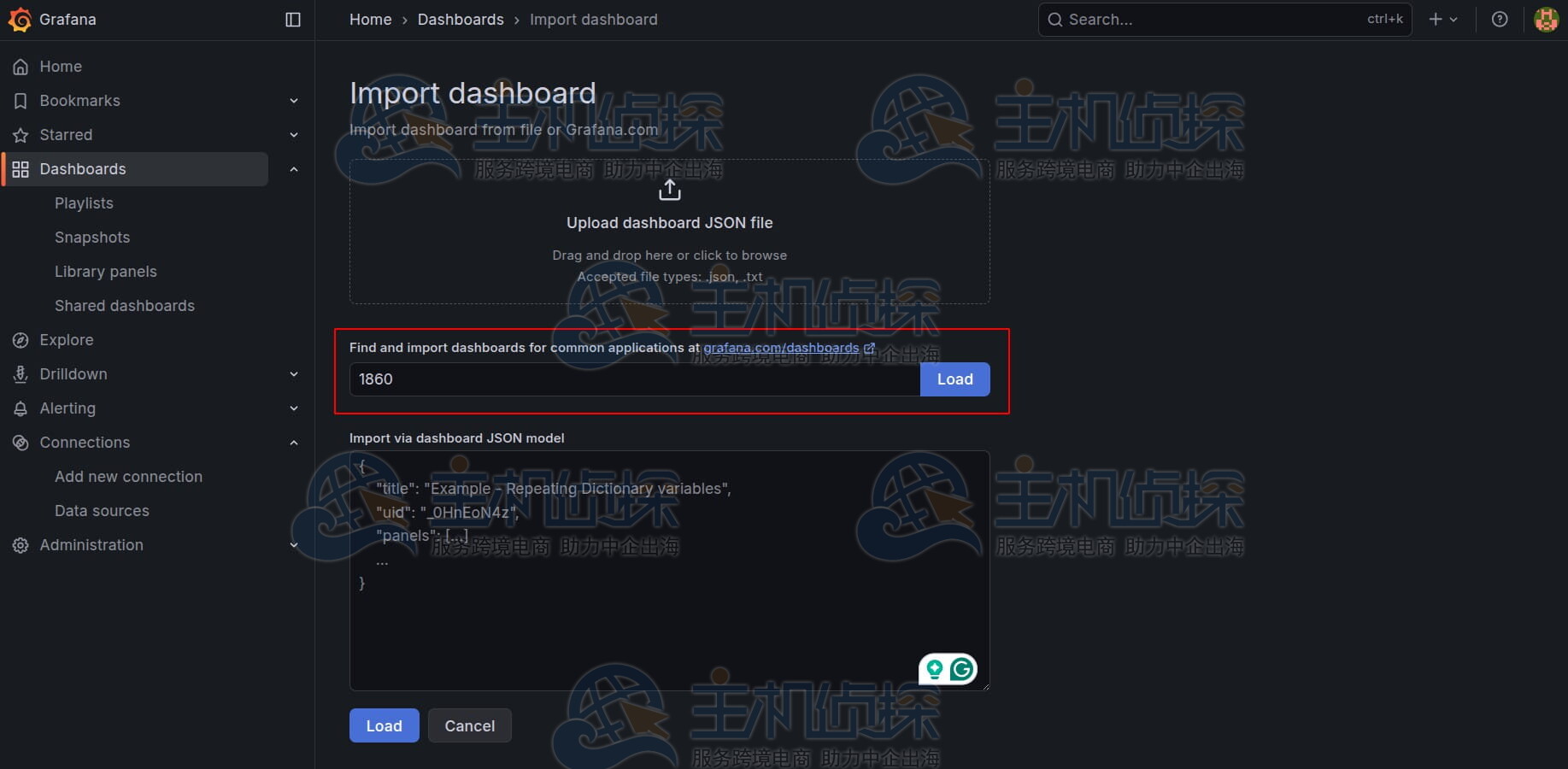
可以导入一个现成的Node Exporter仪表盘:
仪表盘 ID:1860(Node Exporter Full)
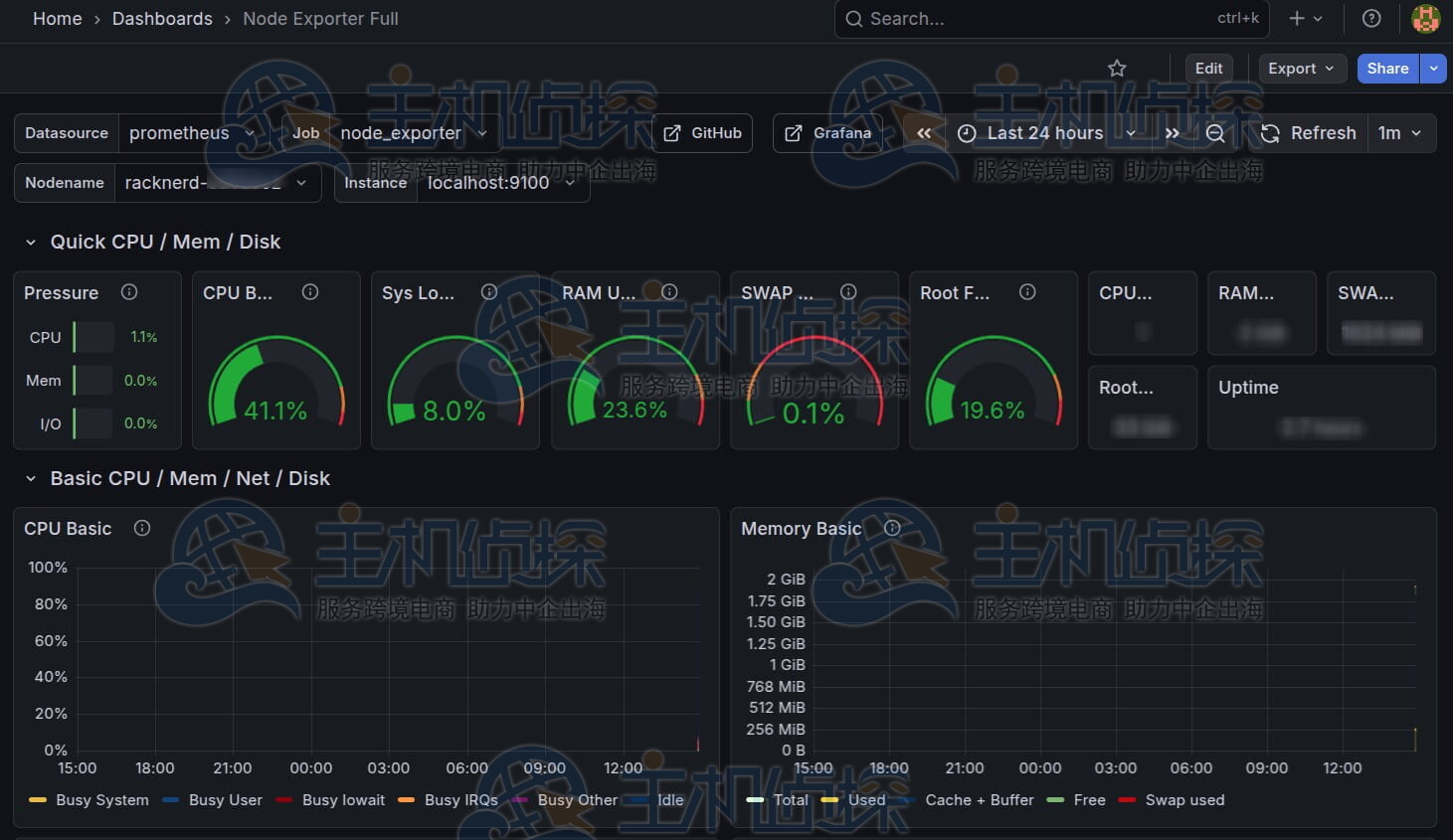
此仪表盘提供以下方面的可见性:
- CPU使用率和平均负载
- 内存和交换空间使用情况
- 磁盘I/O和文件系统健康状况
- 网络吞吐量
Grafana的统一告警功能允许您直接从仪表盘或告警部分定义告警规则。
示例:服务器宕机警报指标查询 (PromQL):
up{job=”node_exporter”} == 0
条件:
如果该值在 1 分钟内为“0”,则触发警报。警报名称:
- 服务器宕机 – Node Exporter 无法访问
- 示例:CPU使用率过高警报
- 100 – (avg by (instance) (rate(node_cpu_seconds_total{mode=”idle”}[5m])) * 100) > 90
- 条件:CPU使用率超过90%,持续5分钟
Grafana支持多种通知集成:
- 电子邮件
- Slack
- Microsoft Teams
- PagerDuty
- Webhooks
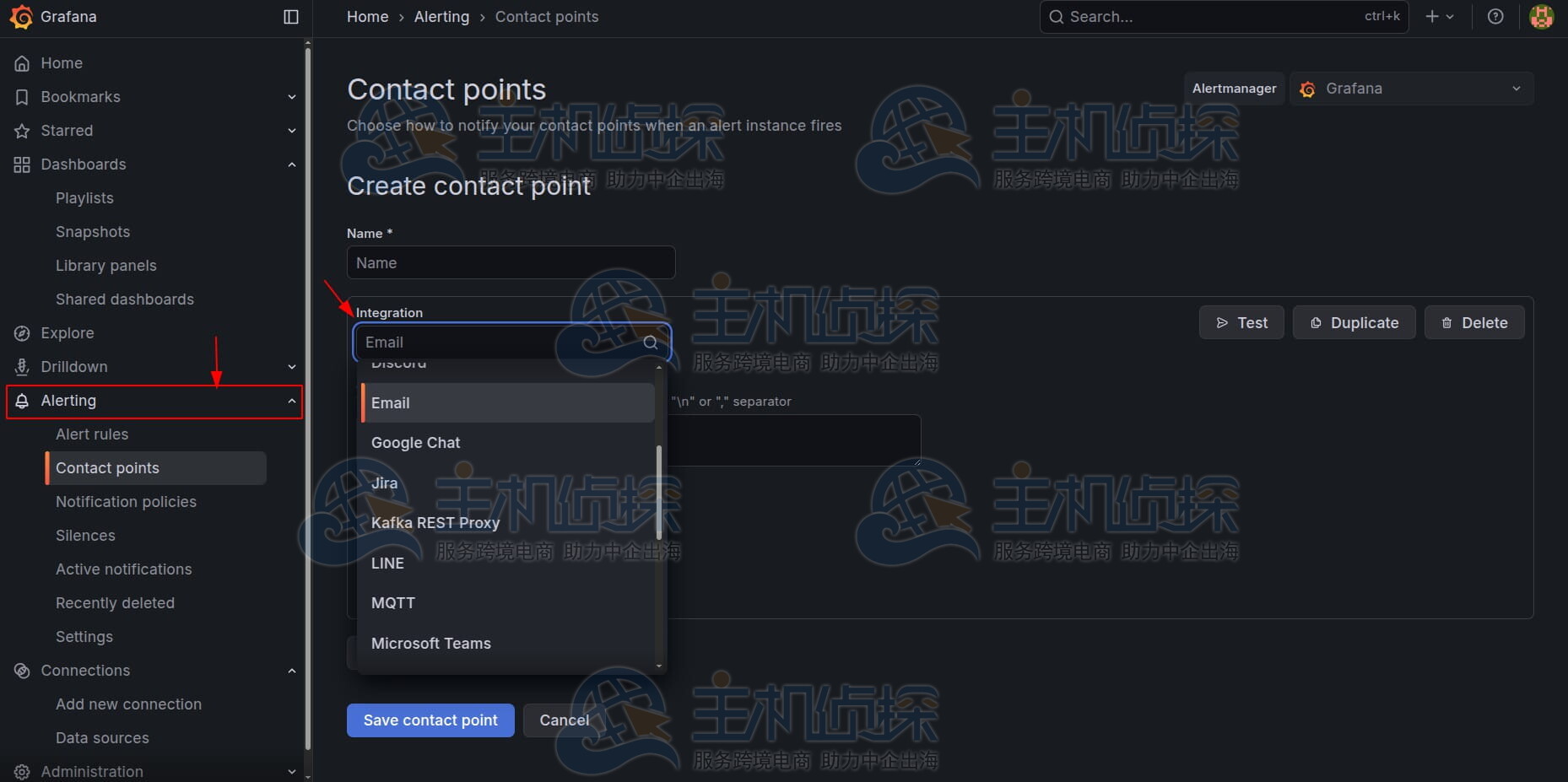
转到“警报”>“联系点”,配置渠道,并通过通知策略将其链接到你的警报规则。
八、测试和调整告警在生产环境中使用告警之前:
1、模拟故障(停止Node Exporter或阻塞端口)
2、验证告警触发和通知送达情况
3、调整阈值以减少噪音和误报
4、添加严重性标签(警告与严重)
九、后续建议1、根据症状而非原始指标发出告警(例如,服务中断与CPU峰值)
2、使用较短的评估窗口进行可用性检查
3、通过对相关告警进行分组来避免告警疲劳
4、记录告警运行手册以便更快地解决问题
5、定期审查和完善告警规则
相关推荐:
《WordPress健康检查和故障排除插件的安装与使用教程》
(本文由美国主机侦探原创,转载请注明出处“美国主机侦探”和原文地址!)

微信扫码加好友进群
主机优惠码及时掌握

QQ群号:164393063
主机优惠发布与交流

{kind=link}
{kind=link}