


NebulaGraph是一款热门的分布式图数据库,提供高吞吐量、低延时的读写能力,提擅长处理千亿节点万亿条边的超大数据集,并保持毫秒级查询延时。本文将带领大家一步步在亚马逊云服务器Amazon EC2上快速部署NebulaGraph数据库,并通过示例场景完成图数据的生成与分析。

一、准备工作
在部署NebulaGraph数据库之前需要创建一个AWS账户,并且具备创建Amazon EC2实例、配置VPC、EBS等资源的权限。登录AWS管理控制台,检查你的资源配额,确保有足够的弹性IP、EC2实例配额等。
AWS官网:点击领取12个月免费Amazon EC2
AWS注册指南:
Amazon EC2创建指南:《亚马逊免费云服务器申请与使用教程》
本次测试环境使用的Amazon EC2机型是c5a.2xlarge,可以提前创建一台。大家可以选择在新的VPC中启动Amazon EC2部署NebulaGraph,也可以使用已有的VPC。部署前请确保在目标区域有可用的EC2密钥对,用于安全登录Amazon EC2实例。
二、Amazon EC2部署NebulaGraphNebulaGraph采用计算与存储分离架构,部署包含graphd、storaged和metad节点。以下是在同一台Amazon EC2上搭建NebulaGraph graphd、storaged和metad 3个节点的过程。
登陆AWS EC2,下载启动 NebulaGraph:
sudo su ubuntu
cd ~
export NEBULA_VERSION=3.4.0
wget https://oss-cdn.nebula-graph.com.cn/package/${NEBULA_VERSION}/nebula-graph-${NEBULA_VERSION}.ubuntu2004.amd64.deb
sudo dpkg -i nebula-graph-${NEBULA_VERSION}.ubuntu2004.amd64.deb
sudo /usr/local/nebula/scripts/nebula.service start all
sudo /usr/local/nebula/scripts/nebula.service status all
下载Nebula console,以便通过命令行查询操作:
wget https://github.com/vesoft-inc/nebula-console/releases/download/v${NEBULA_VERSION}/nebula-console-linux-amd64-v${NEBULA_VERSION}
chmod 111 ./nebula-console-linux-amd64-v${NEBULA_VERSION}
下载Nebula importer,可以更方便、快速地导入数据:
三、图数据生成:创建图空间与导入数据wget https://github.com/vesoft-inc/nebula-importer/releases/download/v${NEBULA_VERSION}/nebula-importer-linux-amd64-v${NEBULA_VERSION}
chmod 111 nebula-importer-linux-amd64-v${NEBULA_VERSION}
本次我们通过处理MySQL数据库中的几张表,来生成实体之间的依赖关系,这个实体对应图中的一个类型的点,如下图所示的V1, 由于V1之间有依赖关系,如果从MySQL解析依赖关系需要多表关联且不确定依赖关系的层数,因此构建图来查找出最长的路径以及依赖和被依赖最多的点。
我们将V1这个类型的点之间的边定义为E1,由于相同的V1之间可能有不同周期的依赖关系,用rank来区分它们。
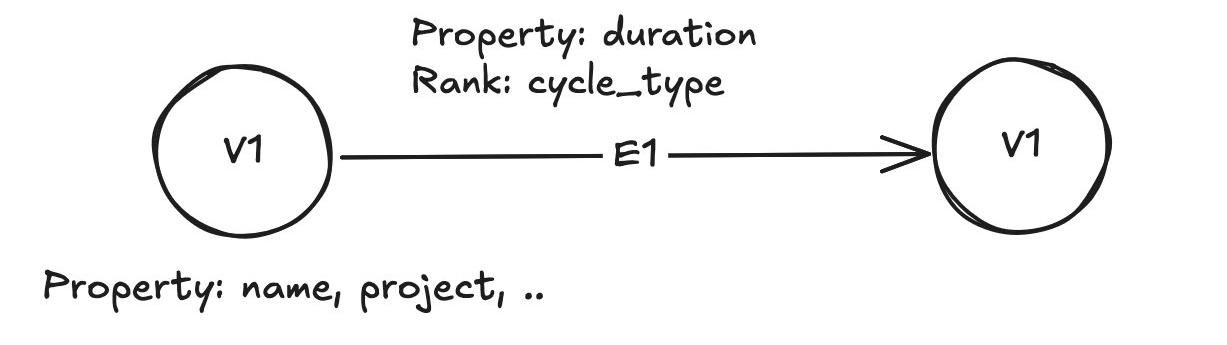
如上图所示,在点和边上设置了property,用来做更进一步的filter,在边上,除了property之外还使用了rank,用来区分两个点之间不同的边,关于property和rank的详细说明如下:
1、Rank的作用
(1)Rank是用来区分同一对起点(src_vid)和终点(dst_vid)之间多条边的唯一标识。
(2)在NebulaGraph中,一条边由四元组唯一标识:(src_vid, edge_type, rank, dst_vid)。
(2)如果两个边的起点、终点和边类型相同,但它们代表不同的关系或不同时刻的关系,就可以通过不同的rank值区分。
(3)默认情况下,rank值为0,如果需要插入多条相同起点和终点的边,必须指定不同的rank。
(4)例如A和B之间有多次转账记录,每次转账可以用不同的时间戳作为rank区分。
2、Property(属性)作用
(1)属性是边或点携带的具体数据字段,用来描述边或点的详细信息。
(2)属性是用户定义的键值对,比如时间、金额、状态等。
(3)属性是边或点的内容,描述边边或点特征和业务含义。
(4)例如转账边或点属性可能包括转账金额、转账时间、备注等。
数据的生成使用python生成csv即可,一种点对应一个csv文件,一种边对应一个csv文件,点csv文件包括点的唯一标识ID,后面的字段为property的具体值;边csv文件第一列是起点,第二列是终点的ID,后面的字段为property以及rank的具体值。
准备好csv文件后,可以按照格式准备以下importer的yaml配置文件,这里需要注意的是不同NebulaGraph的版本的yaml文件格式可能会有些许的差异,因此需要严格按照Nebula Graph的版本去官方文档获取yaml的格式。
config.yaml:
version: v2
description: data import
removeTempFiles: null
clientSettings:
retry: 3
concurrency: 10
channelBufferSize: 128
space: workflow_analysis
connection:
user: “root”
password: “pwd”
address: “127.0.0.1:9669”
postStart: null
preStop: null
logPath: import.log
workingDir: null
files:
– path: ./v1_vertex.csv
failDataPath: v1_vertex_FAIL_DATA
batchSize: 60
limit: null
inOrder: null
type: csv
csv:
withHeader: false
withLabel: false
delimiter: null
schema:
type: vertex
edge: null
vertex:
vid:
index: 0
function: null
type: string
prefix: null
tags:
– name: V1
props:
– name: name
type: int
index: 0
– name: project
type: int
index: 1
– path: ./E1_edge.csv
failDataPath: E1_FAIL_DATA
batchSize: 60
limit: null
inOrder: null
type: csv
csv:
withHeader: false
withLabel: false
delimiter: null
schema:
type: edge
edge:
name: E1
withRanking: null
props:
– name: duration_time
type: int
index: 2
srcVID:
index: 0
function: null
type: string
prefix: null
dstVID:
index: 1
function: null
type: string
prefix: null
rank:
index: 3
vertex: null
之后,通过Nebula Console来创建图的schema:
./nebula-console-linux-amd64-v${NEBULA_VERSION} -addr localhost -port 9669 -u root -p pwd
CREATE SPACE `workflow_analysis` (partition_num = 1, replica_factor = 1, charset = utf8, collate = utf8_bin, vid_type = FIXED_STRING(128));
USE `workflow_analysis`;
CREATE TAG `V1` ( `name` int64 NOT NULL, `project` string NOT NULL) ttl_duration = 0, ttl_col = “”;
CREATE EDGE `E1` ( `duration_time` int64 NOT NULL) ttl_duration = 0, ttl_col = “”;
CREATE EDGE INDEX IF NOT EXISTS e1_duration_index ON E1(duration_time);
CREATE TAG INDEX IF NOT EXISTS v1_name_index ON V1(name);
:sleep 10
REBUILD TAG INDEX v1_name_index;
REBUILD EDGE INDEX e1_duration_index;
最后在Amazon EC2上,通过Nebula impoter导入数据:
四、性能与扩展建议./nebula-importer-linux-amd64-v${NEBULA_VERSION} –config config.yaml
图数据分析实战
# 随机查询3个V1点
MATCH (v:V1) \
RETURN v \
LIMIT 3;# 随机查询3条E1边
MATCH ()-[e:E1]->() \
RETURN e \
limit 3;# 查询name为12345的点
MATCH (v:V1{ name: ‘12345’ }) RETURN v;# 查询从点12345开始、0~1 跳、所有 Edge type 的子图。
GET SUBGRAPH 1 STEPS FROM “12345” YIELD VERTICES AS nodes, EDGES AS relationships;# 找出两个V1之间的最短路径
FIND SHORTEST PATH FROM “12345” TO “45678” OVER * YIELD path AS p;# 某种依赖周期下被依赖最多的点,rank(e)==2代表其中一种依赖周期
MATCH (v:V1) \
WITH v LIMIT 1000000\
OPTIONAL MATCH (v2:V1)-[e:E1]->(v) \
WITH v, e \
WHERE rank(e)==2 \
WITH v, count(e) AS in_degree \
RETURN id(v) AS V1_id, in_degree \
ORDER BY in_degree DESC \
LIMIT 10;# 查询最长的路径前10条,1-100跳
# 用path_length排序, 注意在有环的情况下这条语句不能执行,会打满内存
MATCH p = (v1:V1)-[e:E1*1..100]->(v2:V1) \
WITH p, \
relationships(p) AS rs, \
REDUCE(total = 0, e1 IN relationships(p) | total + e1.d_time) AS total_duration, \
length(p) AS path_length \
WHERE ALL(e2 IN relationships(p) WHERE rank(e2)==1) AND length(p) >= 1 \
RETURN p, total_duration, path_length \
ORDER BY path_length DESC \
LIMIT 10;# 查找所有42条到12345的点,该语句执行不受环的影响,因为它只返回点,并不涉及路径
GO 42 STEPS FROM “12345” \
OVER E1 REVERSELY \
YIELD DISTINCT $$.V1.code AS code ;# 查询”12345″ TO “45678”之间的5跳及以下所有没有环的路径并limit其中一条
FIND NOLOOP PATH FROM “12345” TO “45678” \
OVER E1 \
UPTO 5 STEPS \
YIELD path AS p \
| ORDER BY $-.p DESC \
| LIMIT 1;# 查询点有没有环,如果是多个点,则需要使用nebula python client 一一执行下面的语句
FIND ALL PATH FROM “v1_id1” TO “v1_id1” OVER E1 UPTO 10 STEPS YIELD path AS p
以上语句均扩展自 NebulaGraph官方文档,需要结合数据的实际情况及想要查询的逻辑和结果选择如何去使用。
本次点的数量在10w以内,边的数量在20w以内,使用的机型可以支持高效的查询,如果您的数据量非常大,建议更换机型及使用集群模式来提高查询性能。
生成图数据时,如果是读数据库,建议读非生产环境的数据库生成。在生产环境使用时,需要结合多副本 + 多可用区 + 负载均衡的设计来提高可用性。
相关推荐:
《使用亚马逊Amazon EC2实例部署Qwen-7B-Chat教程》
《Amazon EC2部署DeepSeek-R1蒸馏模型教程》
(本文由美国主机侦探原创,转载请注明出处“美国主机侦探”和原文地址!)

微信扫码加好友进群
主机优惠码及时掌握

QQ群号:164393063
主机优惠发布与交流

{kind=link}
{kind=link}